
1. 데이터 처리 기술
1.1 분산 데이터 저장 기술
대규모 클러스터 시스템 플랫폼은 네트워크상에 분산된 서버들을 클러스터링함으로써 대용량 저장공간과 빠른 처리 성능을 제공한다. 분산 데이터 저장 기술은 네트워크 상에서 데이터를 저장•조회•관리할 수 있으며, 저장 데이터의 정형화 여부와 데이터 모델에 따라 분산 파일시스템과 클러스터 데이터베이스, Key-Value 저장소 정도로 구분할 수 있다.
기존의 아키택쳐는 고가의 마스터 서버에서 많은 역할을 수행하는 중앙 집중 방식이다. 하지만 최근에는 GFS나 BigTable과 같은 플랫폼을 저가의 PC급 서버들로 클러스터를 구성해 마스터 서버의 역할을 축소 시켰으며 장애가 항상 발생할 수 있음을 염두에 두고 디자인됐다.
1.1.1 분산 파일 시스템
대규모 클러스터 시스템 플랫폼은 네트워크 상에 분산도니 많은 서버들을 클러스터로 구성함으로써 대용량의 저장공간과 빠른 처리 성능을 제공할 수 있어야 한다. 이를 위해서는 시스템 확장이 쉽고, 서버 고장과 같은 시스템 장애가 발생하더라도 계속해서 안전하게 서비스를 제공할 수 있는 신뢰성과 가용성을 보장하여야 한다.
비대칭형 클러스터 파일 시스템은 성능과 확장성, 가용성 면에서 적합한 분산 파일 시스템 구조로 최근에 연구와 개발이 활발히 진행되고있다. 또한 파일 메타데이터를 관리하는 전용 서버를 별도로 둠으로써 확장과 안전한 파일서비스를 제공한다. 하지만 서버에 부하가 집중될 수 있기 때문에 메타데이터에 접근하는 경로와 데이터에 접근하는 경로를 분리해 이를 통해 파일 입출력의 성능을 높히면서 독립적인 확장과 안전한 파일 서비스를 진행한다.
1.1.1.1 구글 파일 시스템
구글의 대규모 클러스터 서비스 플랫폼의 기반이 되는 파일 시스템으로 개방되었다. 저가형 서버로 구성된 환경으로 서버의 고장이 빈번히 발생할 수 있다고 가정한다. 대부분의 파일은 대용량이라고 가정한다. 작업 부하는 주로 연속적으로 많은 데이터를 읽는 연산이거나 임의의 영역에서 적은 데이터를 읽는 여러 클라이언트 에서 동시에 동일한 파일에 데이터를 추가하는 환경에서 동기화 오버해드를 최소화 할 수 있는 방법이 요구된다.
파일 쓰기 연산은 주로 순차적으로 데이터를 추가하며 파일에 대한 갱신은 드물게 이뤄져야한다. 낮은 응답 지연시간보다 높은 처리율이 중요하다. 대용량의 데이터를 처리할 수 있는 만큼 처리율이 중요하다.
POSIX 인터페이스를 지원하지 않으며 파일 시스템 인터페이스와 유사한 자체 인터페이스를 지원한다. 그리고 여러 클라이언트에서 원자적인 데이터 추가 연산을 지원하기 위한 인터페이스를 지원한다.
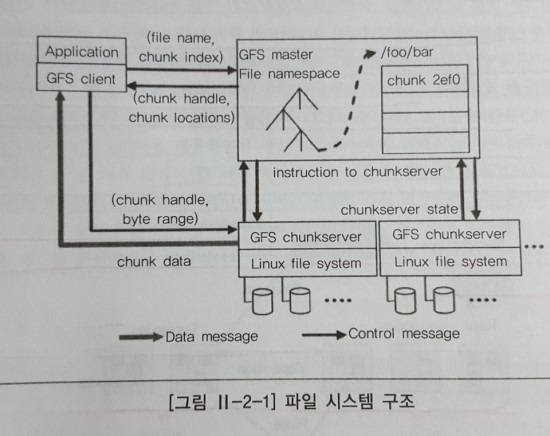
위의 그림에서처럼 파일은 고정된 크기의 chunk들로 나누고 chunk 서버에 저장된다. 각 chunk에 대해 여러 개의 복제본도 chunk 서버에 분산 저장되며, 클라이언트는 파일에 접근하기 위해 마스터로부터 해당 파일의 chunk가 저장된 chunk 서버의 위치와 핸들을 먼저 받아 온다.
데이터 요청은 직접 chunk 서버로 요청한다. 이 때, 해쉬 테이블 구조를 사용함으로써 메모리 상에서 보다 효율적인 메타데이터 처리를 지원한다.
끝으로, 마스터에 대한 장애 처리와 회복을 위해 파일 시스템 이름 공간과 파일의 chunk 매핑 변경 연산을 로깅하고 마스터의 상태를 여러 섀도 마스터에 복제한다.
1.1.1.2 하둡 분산 파일 시스템
아파치의 검색엔진 프로젝트인 루씬의 서브 프로젝트중 하나로 시작했다. 이 후 2008년 1월에 아파치 최상위 프로젝트로 승격되었다. 하둡은 크게 HDFS 와 맵리듀스 라는 기술이 있는데, 먼저 HDFS는 아파치 너치 웹 검색 엔진의 파일시스템으로 개발 되었으며 구글 파일 시스템과 아키텍처 사상을 그대로 구현한 클로닝 프로젝트이다.
하나의 네임 노드와 다수의 데이터 노드로 구성되며, 네임 노드란, 파일시스템의 이름 공간을 관리, 클라이언트로 부터의 파일 접근 요청을 처리하고, 파일 데이터는 블록 단위로 나눠져 여러 데이터노드에 분산 저장된다. 반면 데이터 노드는 클라이언트로부터의 데이터 입출력 요청읋 처리하는데, HDFS에서 파일은 한 번 쓰이면 변경되지 않는다고 가정한다. 주로 스트리밍 접근을 요청, 매치 작업에 적합한 응용을 대상으로 한다.
1.1.1.3 러스터
클러스터 파일 시스템에서 개발한 객체 기반 클러스터 파일 시스템이다. 클라이언트 파일 시스템, 메타데이터 서버, 객체 저장 서버들로 구성되며, 고속 네트워크로 연결되어있다. 구조는 계층화된 모듈 구조이고 TCP/IP, 인피니 밴드, 미리넷과 같은 네트워크를 지원한다. 클라이언트 파일 시스템은 리눅스 VFS애서 설치 할 수 있는 파일 시스템이며, 메타데이터 서버와 객체 저장 서버들과 통신을 하면서 클라이언트 응용에 파일 시스템 인터페이스를 제공한다.
메타데이터 서버는 파일 시스템의 이름 공간과 파일에 대한 메타데이터를 관리하며, 객체 저장 서버는 파일 데이터를 저장하고 클라이언트로부터의 객체 입출력을 요청한다. 메타데이터 서버에서 처리하도록 하는 방식을 사용해 메타데이터에 대한 동시 접근이 적으면 클라이언트 캐시를 이용한 라이트 백 캐시를 사용하고 메타데이터에 대한 동시 접근이 많아지면 클라이언트 캐시를 사용함으로서 발생할 수 있는 오버헤드 수를 줄인다.
1.1.2 데이터베이스 클러스터
데이터를 통합할 때 성능 향상과 가용성을 높이기 위해 데이터베이스차원의 파티셔닝 또는 클러스터링을 이용한다. 이를 통해 파티션 사이의 병렬 처리를 통한 빠른 데이터 건색 및 처리 성능을 얻을 수 있고, 성능의 선형적인 증가 효과를 볼 수 있다. 뿐만 아니라, 특정 파티션에서 장애가 발생하더라도 서비스가 중단되지 않는 고가용성을 확보할 수 있다. 데이터베이스 파티셔닝은 데이터베이스 시스템을 구성하는 형태에 따라 단일 서버 내의 파티셔닝과 다중 서버 사이의 파티셔닝으로 구분할 수도 있고, 공유 디스크와 무공유 디스크로 분류 할 수 있다.
1.1.2.1 무공유
각 데이터베이스 인스턴스는 자신이 관리하는 데이터 파일을 자신의 로컬 디스키에 저장하며 파일들은 노드간에 공유하지 않는다. 각 인스턴스나 노드는 완전히 붠리된 데이터의 서브 집합에 대한 소유권을 가직 있으며, 각 데이터는 소유권을 갖고 있는 인스턴스가 처리한다. 장점은 노드 확장에 제한이 없다는 점이지만, 각 노드에 장애가 발생할 경우를 대비해 별도의 폴트톨러런스(Fault-Tolerance)를 구성해야한다는 것이 단점이다.
1.1.2.2 공유 디스크
데이터 파일은 논리적으로 모든 데이터베이스 인스턴스 노드들과 공유하며 각 인스턴스는 모든 데이터에 접근할 수 있다. 모든 노드가 데이터를 수정할 수 있기 때문에 노드간의 동기화 작업 수행을 위한 별도의 커뮤니케이션 채널이 필요하다. 장점은 높은 수준의 폴트톨러런스(Fault-Tolerance)를 제공한다. 하지만, 클러스터가 커지면 디스크 영역에서 병목현상이 발생한다는 단점이 있다.
가. Oracle RAC 데이터베이스 서버
일반적인 4 노드 RAC 구성 모델이다. 클러스터의 모든 노드에서 실해되며 데이터는 공유 스토리지에 저장되며, 클러스터의 모든 노드는 데이터베이스의 모든 테이블에 동등하게 엑세스하며 특정 노드가 데이터를 소유하는 개념이 없다.
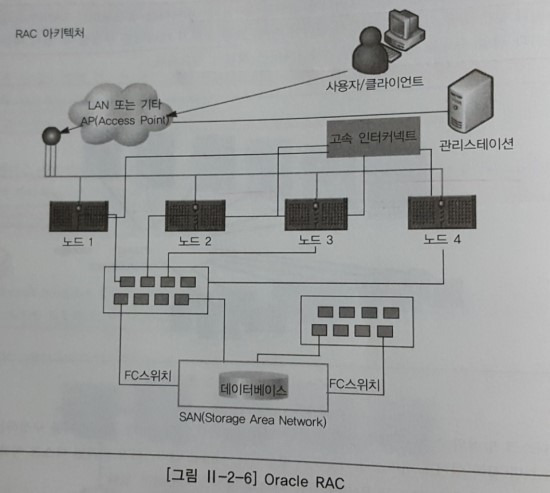
Oracle RAC의 특징은 다음과 같다.
가용성
클러스터의 한 노드가 어떤 이유로 장애를 일으키면 Oracle RAC는 나머지 노드에서 계속 진행한다. 장애 발생한 노드에 연결된 모든 응용 프로그램들은 다시 연결되어 나머지 노드에 분산된다
확장성
추가 처리 성능이 필요하면 응용 프로그램이나 데이터베이스를 수정할 필요 없이 새 노드를 클러스터에 쉽게 추가할 수 있다.
비용 절감
RAC는 표준화된 소규모 저가형 상용 하드웨어의 클러스터에서도 고가의 SMP 시스템만큼 효율적으로 응용 프로그램을 실행함으로써 하드웨어 비용을 절감한다. 도입 비용 때문에 확장성이 중요한 데이터보다 고가용성을 요구하는 데이터에 많이 이용되기 때문에 일반적으로 4노드 이상 잘 구성하지 않는다.
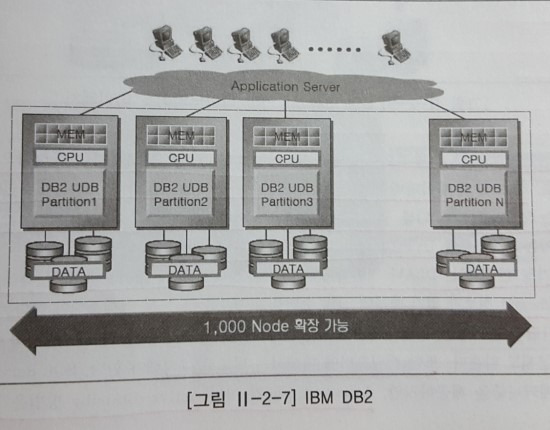
나. IBM DB2 ICE(Integrated Cluster Environment)
CPU, 메모리, 디스크를 파티션 별로 독립적으로 운영하는 무공유 방식의 클러스터링을 지원한다. 애플리케이션은 여러 파티션에 분산된 데이터베이스를 하나의 데이터베이스로 보게 되고 데이터가 어느 파티션에 존재하고 있는지 알 필요가 없다. 만약, 데이터와 사용자가 증가하면, 애플리케이션의 수정 없이 기존 시스템에 노드를 추가하고, 데이터를 재분배함으로써 시스템의 성능과 용량을 일정하게 유지할 수 있다.
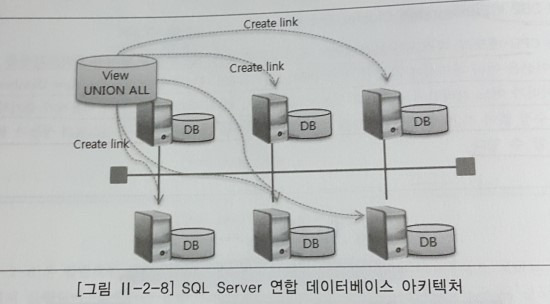
다. 마이크로소프트 SQL Server
데이터베이스 형태로 여러 노드로 확장할 수 있는 기능을 제공한다. 연합 데이터베이스는 디스크 등을 공유하지 않는 독립된 서버에서 실행되는 서로 다른 데이터베이스들 간의 논리적인 결합이며 네트워크를 이용하여 연결한다. 데이터는 관련된 서버들로 수평적으로 분할되며, 테이블을 논리적으로 분리해 물리적으로는 분산된 각 노드에 생성하고 각 노드의 데이터베이스 인스턴스 사이에 링크를 구성한 후 모든 파티션에 대해 UNION ALL을 이용하여 논리적인 뷰를 구성하는 방식으로 분산된 환경의 데이터에 대한 싱글 뷰를 제공한다.
하지만, 가장 큰 문제는 DBA나 개발자가 파티셔닝 정책에 맞게 테이블과 뷰를 생성해야 하고 전역 스키마 정보가 없기 때문에 질의 수행을 위해 모든 노드를 엑세스 해야한다는 점이다. 이 때문에 페일오버(Fail Over)에 대해서는 별도로 구성해야한다.
라. MySQL
무공유 구조에서 메모리(디스크도 제공) 기반의 데이터베이스의 클러스터링을 지원하며, 특정한 하드웨어 및 소프트웨어를 요구하지 않고 병렬 서버구조로 확장이 가능하다. 클러스터에 대한 구성요소들은 다음과 같다.
관리노드
클러스터를 관리하는 노드로 클러스터 시작과 재구성 시에만 관여한다.
데이터노드
클러스터의 데이터를 저장하는 노드
MySQL노드
클러스터 데이터에 접근을 지원하는 노드
데이터의 가용성을 높이기 위해 데이터를 다른 노드에 복제시키며, 특정 노드에 장애가 발생하더라도 지속적인 데이터 서비스가 가능하다. 뿐만 아니라, 장애가 났던 노드가 복구되어 클러스터에 투입된 경우에도 기존 데이터와 변경된 데이터에 대한 동기화 작업이 자동으로 수행된다. 데이터는 동기화 방식으로 복제되며 작업을 위해 일반적으로 데이터 노드 간에는 별도의 네트워크를 구성한다.
또 다른 특징으로는 디스크 기반의 클러스터링을 제공한다. 디스크 기반 클러스터링에서는 인덱스가 생성된 칼럼은 기존과 동일하게 메모리에 유지되나 인덱스를 생성하지 않은 칼럼은 디스크에 저장된다. 클러스터링과 관련해서 구체적인 내용은 다음과 같다.
[클러스터링 구현 시 유의사항]
1. 파티셔닝에 대해서는 LINEAR KEY 파티셔닝만 가능하다.
2. 클러스터 참여하는 노드 수는 SQL노드, 데이터 노드, 매니저를 포함해 전체 255개로 제한한다.
3. 트랜젝션 수행 중 롤백을 지원하지 않으므로 작업수행 중에 문제가 발생하엿다면 전체 트랜잭션이전으로 롤백해야한다.
4. 하나의 트랜잭션에 많은 데이터를 처리하는 경우 메모리 부족 문제가 발생할 수 있으며
5. 여러 개의 트랜잭션으로 분리해 처리하는 것이 좋다.
6. 컬럼명은 길이 31자, 데이터 베이스와 테이블 명은 122자까지로 제한된다.
7. 클러스터에서 생성할 수 있는 테이블 수는 최대 20320개이다.
8. 모든 클러스터의 기종은 동일해야한다.
9. 테이블 키는 최대 32개로 제한한다.
10. 운영 중에 노드를 추가/삭제할 수 없다.
11. 디스크 기반 클러스터인 경우 테이블스페이스는 총 2^32개이다.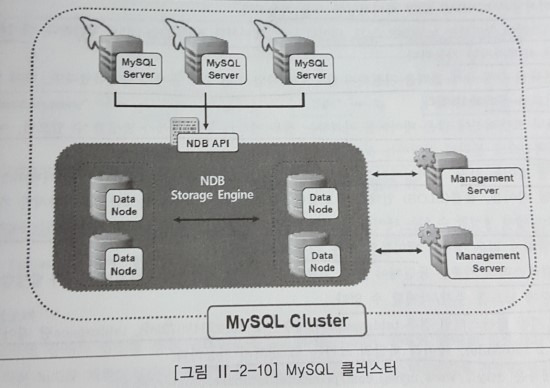
1.1.3 NoSQL
Key와 Value 형태로 자료를 저장하고 빠르게 조회 가능한 자료 구조를 제공하는 저장소이며, 복잡한 JOIN연산 기능은 지원하지 않지만 대용량 데이터와 대규모 확장성을 제공한다는 장점이 있다.
1.1.3.1 구글 빅테이블
Mulit-dimension sorted hash map을 파티션하여 분산 저장하는 저장소다. 데이터는 Row-key의 사전적 순서로 정렬, 저장된다. 이 때, Row는 n개의 column-family를 가질 수 있으며 column-family에는 column key, value, timestamp 형태로 구성된다.
동일한 column key에 대해 타임스탬프는 다른 여러 버전의 값이 존재할 수 있으며, 데이터(map)의 키 값 또는 정렬 기준은 "rowkey + columnkey + timestamp"가 된다. 특징으로는 Fail Over 에 대한 처리와 AppEngine 이 있다.
Fail over
특정 노드에 장애가 발생할 경우 빅테이블의 마스터는 장애가 발생한 노드에서 서비스되던 Tablet을 다른 노드로 재할당시킨다. 재할당 받은 노드는 구글 파일 시스템에 저장된 변경 로그 파일, 인덱스, 파일, 데이터 파일 등을 이용해 데이터서비스를 위한 초기화 작업을 수행한 후 데이터 서비스를 한다.
빅테이블의 SPOF는 마스터다. 분산 락 서비스를 제공하는 Chubby를 이용해 Master를 계속 모니터링 하다가 마스터에 장애가 발생하면 가용한 노드에 마스터 역할을 수행하도록 한다.
AppEngine
빅테이블 내에서 운영되어 애플리케이션의 데이터 저장소를 제공하며, 내부적으로는 빅테이블을 이용한다, 사용자 테이블을 생성할 경우 빅테이블의 테이블로 생성되는 것이 아니라 빅테이블의 특정 테이블의 한 영역만을 차지하게 된다. 빅데이블에서는 별도의 사용자 정의 인덱스를 제공하지않는 반면 AppEngine에서는 사용자가 수행하는 쿼리를 분석하여 자동으로 인덱스를 생성해준다. 공통된 특징으로는 수백 테라바이트에서 수 페타바이트 규모의 데이터를 다루고 있으며, 실시간으로 데이터를 저장하거나 조회하고 주기적인 배치 작업을 통해 데이터를 분석하고, 분석된 결과를 다시 실시간으로 서비스하는 패턴을 갖고 있다.
1.1.3.2 아마존 SimpleDB
아마존의 데이터 서비스 플렛폼이며, 웹 애플리케이션에서 사용하는 데이터의 실시간 처리를 지원한다. 아마존의 내부 서비스 간 네트워크 트래픽은 무료이고 외부와의 In/Out 트래픽에는 요금을 부과하는 아마존 서비스의 가격 정책을 적용한다. 특징 중 하나로, 사용 시에는 하나의 데이터에 대해 여러 개의 복제본을 유지하는 방식으로 가용성을 높인다. 두번째로 Eventual Consistency는 트랜잭션 종료 후 데이터는 모든 노드에 즉시 반영되지 않고 초단위로 지연되어 동기화 된다. 마지막 특징은 관계형 데이터 모델과 표준 SQL을 지원하지 않으며 전용 쿼리 언어를 이용하여 데이터를 조회한다. 구성은 크게 도메인과 Items, Attribute 로 구성된다.
도메인
관계형 데이터베이스를 테이블과 동일한 개념으로 하나의 도메인에는 최대 10GB의 데이터를 저장할 수 있으며, 사용자는 100개의 도메인을 가질 수 있다. 사용자는 최대 1000GB의 데이터를 SimpleDB에 저장할 수 있다.
Items
관계형 데이터베이스의 레코드와 동일한 개념으로 독립적인 객체를 나타내고 하나 이상의 Attribute를 가진다. 특정 Attribute에는 여러 개의 값을 저장할 수 있으며, 최대 256개의 Attribute를 가질 수 있다.
Attribute
관계형 데이터베이스의 컬럼과 동일한 개념으로, 사용하기 전에 미리 저장할 필요가 없다, Name과 Value 쌍으로 데이터를 저장하고 저장되는 데이터의 Name이 Attribute의 이름이 된다.
1.1.3.3 마이크로소프트 SSDS
2008년 4월에 베타 서비스를 실시한 데이터 서비스이며, 고가용성을 보장하는 특징이 있다. 구성으로는 컨테이너와 엔터티로 구성되고, 엔터티에는 name-value 형태의 property 가 여러 개 존재할 수 있다.
컨테이너
테이블과 유사한 개념이나 하나의 컨테이너에 여러 종류의 엔티티를 저장 가능
엔터티
레코드와 유사한 개념 하나의 엔티티는 여러 개의 property를 가질 수 있다.
Property
name-value쌍으로 저장된다.관계형 데이터베이스에서는 엔티티를 구분하고 엔티티별로 테이블을 생성하는 것이 일반적이다.
위와 같은 방식으로 컨테이너를 구성할 경우 많은 컨테이너가 생성되고 여러 노드에 분산 관리할 수 있는데, 사용하는 쿼리는 하나의 컨테이너만을 대상으로 적용한다.
1.2 분산 컴퓨팅 기술
최근 컴퓨팅 환경은 저가형 서버들을 클러스터링하고 다양한 리소스(CPU, 메모리, 하드 디스크, 파일, 프로세스)들을 끌어 모아 표준화된 대규모 고성능 컴퓨팅 플랫폼을 구축하는 일에 많은 노력을 기울이고 있다. 대용량 데이터를 다루고 있는 다양한 응용 분야에서도 중요한 역할을 수행하게 되는데 계산 중심의 수학, 과학 분야뿐만 아니라 데이터 중심의 텍스트 마이닝과 로그 모델링 같은 정보분석 분야에서도 활용도가 높다.
1.2.1 MapReduce
분할 정복 방식으로 대용량 데이터를 병렬로 처리할 수 있는 프로그래밍 모델로, 구글에서 MapReduce 방식의 분산 컴퓨팅 플렛폼을 구현해 성공적으로 적용함으로써 더욱 유명해졌다. 오픈소스인 Hadoop MapReduce 프레임워크와 동일한 기능을 지원하는데, 5개의 Map Task가 생성되고, Map 과정에서 생산된 중간 결과물들을 Reduce Task들이 받아와서 정렬 및 필터링 작업을 거쳐서 최종 결과물을 만들어 낸다.
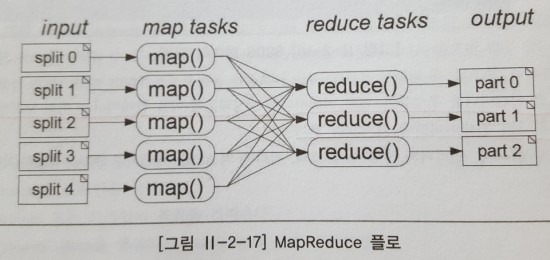
1.2.1.1 구글 MapReduce
대부분의 연산 방식들은 직관적이었지만 처리해야할 데이터가 매우 컸기 때문에 수백 대 혹은 수천 대의 서버들에 분산 처리해야만 원하는 시간 안에 작업을 마칠 수 있었다. 개발자가 연산의 병렬화, 데이터 분산, 장애 복구 등의 작업들을 직접 처리해야되기 때문에 코드의 복잡성이 증가하고 많은 개발 시간이 소요된다. 동작원리는 다음과 같다.
[구글 Mapreduce 동작원리]
1. Map에서 Key-Value 쌍들의 입력을 받는다.
2. 하나의 Key-Value쌍은 사용자가 정의한 Map 함수를 거치면서 다수의 새로운 Key-Value쌍들로 변환되고 로컬 파일 시스템에 임시 저장된다.
이 과정에서 자동으로 Shuffling 및 group by 정렬이 된 후 Reduce 입력 레코드로 들어가게 된다.
(형식은 Key-Value 의 리스트이다.)
3. Reduce의 입력 레코드들은 사용자가 정의한 Reduce 함수를 통해 최종 Output으로 산출된다.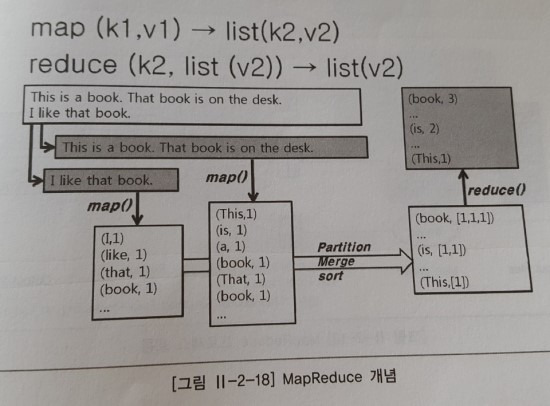
위의 내용을 기반으로 구글 맵리듀스가 실행되는 내용을 살펴보자.
[실행 과정]
1. 사용자가 MapReduce 프로그램을 작성해 실행하면 마스터는 사용자의 프로그램에서 지정한
입력 데이터 소스를 가지고 스케줄링을 한다.
보통 split의 단위는 블록 사이즈인 64MB 또는 128MB이며 split 수만큼 Map Task들이 워커로부터
fork됨과 동시에 실행돼 Output을 로컬 파일 시스템에 저장한다.
이 때, Output 값들은 Partitioner라는 Reducce 번호를 할당해 주는 클래스를 통해
어떤 Reduce로 보내질지 정해진다.
특별히 지정되지 않으며 Key는 hash 값을 Reduce 의 개수로 Modular(나머지연산) 계산한 값이
부여되어 동일한 Key들은 같은 Reduce로 배정된다.
2. Map 단계가 끝나면 원격의 Reduce 워크들이 자기에 할당된 Map의 중간 값들을 네트워크로 가지며,
사용자의 Reduce 로직을 실행해 최종 산출물을 얻어낸다.
3. Reduce의 개수는 Map의 개수보다 적으며, 이 때 Map의 중간 데이터 사이즈에 따라 성능이 좌우된다.
4. Map의 단계를 거치면서 데이터 사이즈가 크게 줄어들고 성능이 좌우된다.
Map 단계를 거치면서 데이터 사이즈가 크게 줄어들고, 줄어든 크기만큼 Reduce 작업 시 오버헤드도 줄어들기 때문에 성능상 이점이 많다.
하지만, 정렬 같은 작업은 입력사이즈가 줄지 않고 그대로 전해지기 때문에 수행 능력이 저하되므로 정렬같은 작업에는 적합하지 않다.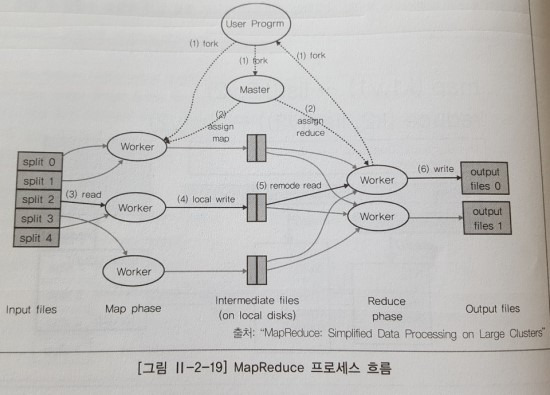
마지막으로 MapReduce 작업에 대한 Fault Tolerance이 어떻게 적용되는지 살펴보자. 마스터는 모든 워크들의 Task 상태정보를 가지고 있다가 특정 워커의 태스크가 더 이상 진행되지 않거나 상태 정보를 일정한 시간동안(Timeout) 받지 못하면 Task에 문제가 있다고 결론을 내리며 이 후 장애 복구 시에는 해당 Task 가 처리해야할 데이터 정보만 다른 워커에 전해 주면 받은 데이터 정보를 인자로 새로운 Task를 재실행하면 된다.
1.2.1.2 Hadoop Reduce
아파치 오픈 소스 프로젝트인 하둡 MapReduce는 구글에서 발표한 논문을 바탕으로 Java 언어로 구현한 시스템이다. 분산 파일 시스템인 HDFS와 이번에 소개할 Hadoop MapReduce가 하둡의 핵심 구성요소이며, 아파치 검색엔진 프로젝트인 Lucene의 서브프로젝트이다. 전 세계적으로 다양한 산업 영역에서 수많은 업체가 실제 서비스에 활용할 정도로 성능과 안정성이 검증된 상태이다.
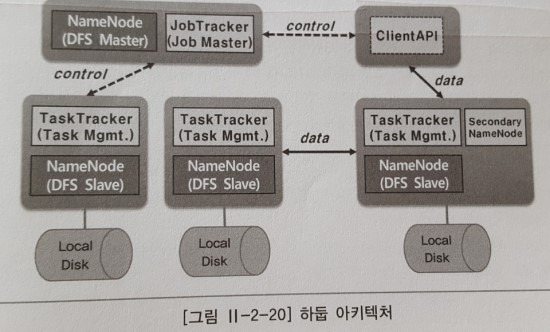
하둡 맵리듀스의 아키텍처는 다음과 같다.먼저 데몬 관점에서 보면, 하둡은 4개의 구성요소를 가지고 있다. 이 중 네임노드(Namenode), 데이터노드(Datanode) 에 대해서는 앞서 설명했기 때문에 이번에는 넘어가도록 하자. 다음으로 살펴볼 JobTracker는 MapReduce 시스템의 마스터를 의미하고, TaskTracker는 워크 데몬을 말한다.
동작에 관해서는 3초에 한 번씩 TaskTracer가 JobTracker에게 한번씩 주기적으로 하트비트를 보내 살아있다는 것을 알린다. 하둡 작업을 실행하면 프로그램 바이너리와 입출력 디렉터리와 같은 환경정보들이 JobTracker 에게 전송되는데, JobTracker에서는 작업을 다수의 Task로 쪼갠 후 그 Task들을 어떤 TaskTracker에게 보내면 데이터 지역성을 보장할 지도 감안해 내부적으로 스케줄링해 큐에 저장한다. 이 후 TaskTracker에서 Heartbeat를 보내면 JobTracker는 먼저 해당 TaskTracker에게 할당된 Task가 있는 지 큐에서 살펴본다. Task가 존재하면 하트비트의 Response 메시지에 Task 정보를 실어서 TaskTracker에게 보낸다.
이번에는 하둡의 성능에 대해서 알아보자. 하둡의 MapReduce에서 sort는 어떠한 작업을 실행하더라도 Map에서 Reduce로 넘어가는 과정에서 항상 발생하는 내부적인 프로세스이다. 이 때, Sort 작업은 데이터가 커질수록 처리 시간이 선형적으로 증가한다. 이는 클러스터의 구성 서버들의 숫자를 늘림으로써 처리시간을 줄일 수 있는 것은 아니다. 즉, 플랫폼 자체적으로 선형 확장성을 갖고 있어야 처리 시간을 줄일 수 있는 것은 아니기 때문에, 하둡과 같은 분산컴퓨팅 플랫폼의 성능과 확장성을 동시에 측정할 수 있는 좋은 실험이라고 할 수 있다.
1.2.2 병렬 쿼리 시스템
개발자들에게 구현하려는 알고리즘에만 포커싱할 수 있도록 간단한 프로그래밍 모델을 제공한다. 간단한 프로그램이 모델이지만 일부 사용자들에게는 새로운 개념이기 때문에 쉽지 않다. 이에 따라 직접 코딩하지 않고도 쉽고 빠르게 서비스나 알고리즘을 구현하고 적용해 볼 수 있는 환경에 대한 필요성이 대두되었다.
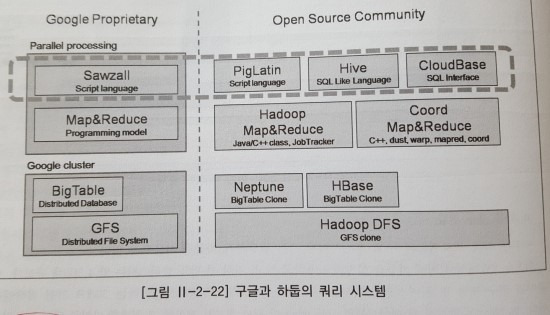
1.2.2.1 구글 Sawzall
MapReduce를 추상화한 스크립트 형태의 병렬 프로그래밍 언어이며, 사용자가 이해하기 쉬운 인터페이스를 제공하여 MapReduce의 개발 생산성을 높였다. 이로 인해, MapReduce에 대한 이해가 없는 사용자들도 쉽게 병렬 프로그래밍이 가능해졌다.
1.2.2.2 아파치 Pig
야후에서 개발한 오픈소스 프로젝트화한 데이터 처리를 위한 고차원 언어로, Hadoop MapReduce에서 동작하는 추상화된 병렬 처리 언어이며 현재 아파치 하둡의 서브 프로젝트이다. 2007년에 개발을 시작 이후 2~10배까지 개선시켰고, 네이티브 MapReduece와 비교한 성능은 90%이다. 개발하게 된 이유는 Map의 Output이 다른 Map의 Input이 되고, Reduce의 Output은 다른 Map의 Input이 되는 Chainning이 되어야하기 때문에 MapReduce 자체적으로는 지원하기 버거웠다.
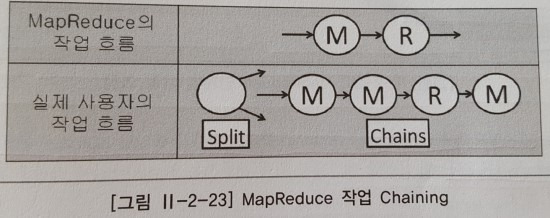
기본적으로 무공유 구조이기 때문에 일반 RDB(관계형 DB)로는 쉽게 해결할 수 있는 JOIN 연산이 복잡해진다. 하지만, Pig를 사용해서 처리할 경우 10줄 이내로 간단하게 해결할 수 있다.

1.2.2.3 아파치 Hive
페이스 북에서 개발한 데이터 웨어하우징 인프라로, 하둡 플렛폼에서 동작하며, 사용자가 쉽게 작성할 수 있도록 SQL 기반의 쿼리 언어와 JDBC를 지원한다. 주로 Hadoop-Streaming을 쿼리 내부에 삽입해 사용할 수 있다. 개발 당시, 페이스북은 상용 DBMS를 사용하고 있었으나 시간이 지남에 따라 데이터의 양이 급 증가하였고, 관리 및 운영비영의 절감을 위해 하둡으로 교체하면서 필요한 기능들과 사용자를 위한 CLI(Command Line Interface), 코딩없이 애드 훅 질의 기능, 스키마 정보들의 관리 기능들을 하나씩 구현하면서 만들어졌다. 이로 인해 일일 데이터 처리량은 수십 PB 정도이며 동시에 수천 건 이상의 애드훅 분석 쿼리 작업을 수행하고 있다. 다음으로 하이브의 아키텍처를 살펴보자. 내용은 다음과 같다.
메타스토어 (MetaStore)
Raw File들의 콘텐츠를 일정의 테이블의 컬럼처럼 구조화된(Structed) 형태로 관리할 수 있게 해주는 스키마 저장소이다. 별도의 DBMS를 설정하지 않으면 Embedded Derby를 기본으로 하며, 사용자는 CLI를 통해 Join이나 Group by 같은 SQL 쿼리를 한다.
파서(Parser)
쿼리를 구문 분석을 하고 MetaStore의 테이블과 파티션 정보를 참조해 Execution Plan을 만들어 낸다. 만들어진 Plan은 Execution Engine으로 보내진다.
실행엔진 (Execution Engine)
Execution Plan을 JobTracker와 네임노드와 통신을 담당하는 창구 역할을 하면서 MapReduce 작업을 실행하고 파일을 관리한다.
하이브 역시 SQL의 일부 기능을 지원하는데, 구체적인 내용은 다음과 같다.
DDL
- 테이블 생성, 삭제, 변경
- 테이블 스키마 변경
- 테이블 및 스키마 조회
DML
- 로컬에서 DFS로 데이터 업로드
- 쿼리 결과를 테이블이나 로컬 파일 시스템, DFS애 저장
Query
- select, group by, sort by, join, union, sub query
1.2.3 SQL on Hadoop
하둡과 하이브는 대용량 데이터를 배치 처리하는데 최적화 되어있지만 실제 업무에서는 배치 처리뿐만 아니라 데이터를 실시간으로 조회하거나 처리해야 하는 일들이 많다. 이에 따라 실시간 SQL 질의 기술들이 적용되었다.
1.2.3.1 임팔라
클라우데라는 드레멜의 논문인 “Interactive Analysis of Web-Scale Datasets”를 읽고 하둡 상에서 실시간 애드혹 질의가 가능할 것 같다는 기술적 영감을 얻어 개발되었다. 2013년 5월에 정식 버전 배포되었으며, 주로 분석과 트랙잭션 처리를 모두 지원하는 것을 목표로 만들어진 SQL 질의 엔진이라고 볼 수 있다. 고성능을 낼 수 있도록 자바 대신 C++을 이용, 맵리듀스를 사용하지 않고 실행 중에 최적화된 코드를 생성해 데이터를 처리한다.
1.2.3.2 임팔라 동작 방식
모든 노드에 임팔라 데이몬이 구동되며, 사용자는 이 데몬들이 구동된 임의의 노드에 JDBC나 ODBC 또는 임팔라셀을 이용하여 질의를 요청할 수 있다. 또한 하둡에서 JobTracker와 TaskTracker에게 지역성을 고려해 태스크를 할당하는 것과 유사한 방식으로 동작한다.
1.2.3.3 임팔라의 SQL 구문
임팔라에서 지원하는 SQL 구문은 다음과 같다.
DDL
데이터 테이블 생성(CREATE), 변경 및 파티션 추가(ALTER), 삭제(DROP), 조회(SHOW, DESCRIBE),
DML
데이터 조회(SELECT), 입력(INSERT), 변경은 지원불가, 삭제는 테이블 삭제 시 데이터 삭제가능
내장 함수
- 수학 함수: 절대값 반환, 코사인값 반환, 로그값 반환
- 타입 반환: 날짜값 반환, 포타임 변환, 현재 시간 반환
- 조건문: IF, CASE(분기)
- 문자열 함수: 아스키 코드값 변환, 문자열 병합, 정규 표현식
1.2.3.4 임팔라 데이터 모델
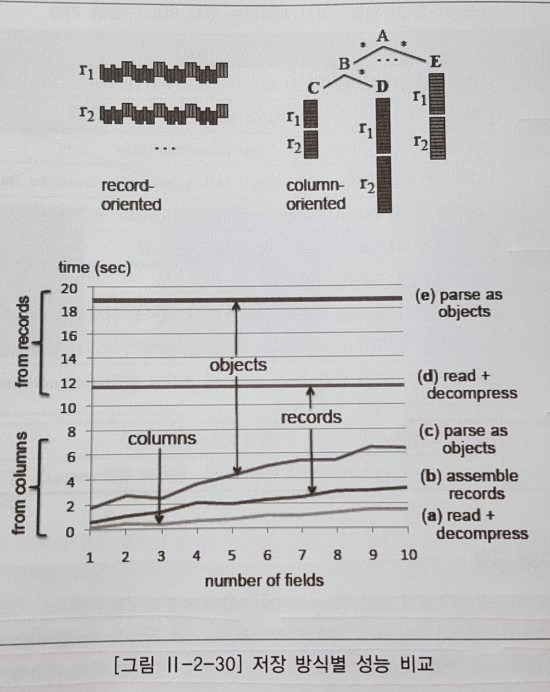
하둡 분산 파일 시스템에 데이터를 저장한다. 이 때, 어떤 저장 포맷을 사용하느냐에 따라 데이터 조회시 처리 성능이 달라진다. 하둡의 기본 파일 포맷인 텍스트나 시퀀스 파일은 로우 단위의 데이터 저장 방식을 사용할 수 있으며, 컬럼 단위의 파일 저장 포맷인 RCFile을 사용할 경우, 데이터 처리과정에서 발생하는 디스크 입출력 양은 현저하게 줄일 수 있다.
이유는 컬럼 단위로 저장 포맷을 사용하면 읽고자 하는 컬럼만큼의 디스크 입출력이 발생하기 때문에 결과적으로 처리 성능을 개선할 수 있다. 뿐만 아니라, 조회하는 질의는 저장 포맷에 의해 성능이 영향을 받지 않는다. 또한 테스트한 결과 컬럼 파일 포맷을 사용했을 때 처리 시간이 덜 걸린다.- 적은 수의 컬럼을 읽을수록 훨씬 빠른 처리 성능을 보여주고 있으며, 기존의 로우 파일 포맷을 사용해 레코드를 읽을 때는 하나의 컬럼에 접근해도 항상 전체를 읽는 것과 같은 처리 시간을 보여줄 수 있다.
1.3 클라우드 인프라 기술
클라우드 인프라 기술은 크게 클라우드 컴퓨팅 과 서버 가상화 기술로 볼 수 있다. 클라우드 컴퓨팅은 동적으로 확장할 수 있는 가상화 자원들을 인터넷으로 서비스할 수 있는 기술로 SaaS, PaaS, IaaS로 나뉜다. 서버 가상화 기술은 인프라 기술 중 하나로 물리적인 서버와 운영체제 사이에 적절한 계층을추가해 서버를 사용하는 사용자에게 물리적인 자원은 숨기고 논리적인 자원만을 보여주는 기술을 말한다.
서버 가상화는 하나의 서버에서 여러 개의 애플리케이션, 미들 웨어, 운영체제들이 서로 영향을 미치지 않으면서 동시에 사용할 수 있도록 해준다. 서버는 x86 계열이며, 특징으로 하드웨어, CPU, 운영체제의 공급 업체가 모두 다르다는 점이다.
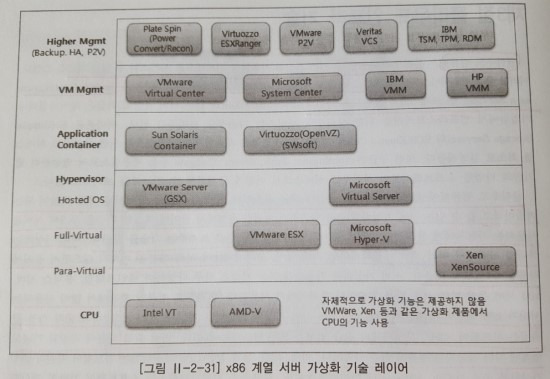
클라우드 인프라를 구성했을 때 얻을 수 있는 효과들은 다음과 같다.
가상머신 사이의 데이터 보호
하나의 물리적인 서버에서 운영중인 서로 다른 가상 머신들 사이의 접속은 정상적인 네트워크 접속만을 허용한다.
예측하지 못한 장애로부터 보호
가상머신에서 수행중인 애플리케이션의 장애가 다른 가상머신에는 전혀 영향을 미치지 않는다.
공유 자원에 대한 강제 사용의 거부
하나의 가상머신은 할당된 자원 이상을 가져가는 것을 차단할 수 있다.
서버 통합
서버 가상화를 통해 얻을 수 있는 가장 일반적인 효과로, 서비스, 데이터, 사용자 등의 증가로 더 많은 컴퓨텅 자원이 필요해졌지만 데이터 센터의 공간, 전원, 냉각 장치는 제한적이다. 기존 서버의 용량을 증설하고 가상머신을 추가함으로써 동일한 데이터 센터의 물리적 자원 (공간, 전원 등)을 이용하면서 더 많은 서버를 운영할 수 있다.
자원 할당에 대한 증가된 유연성
수시로 변화하는 각 가상머신의 자원 요구량에 맞추어 전체 시스템 자원을 재배치함으로써, 자원 활용도를 극대화할 수 있다.
테스팅
다양한 운영체제나 운영환경에서 테스트가 필요한 경우, 새로운 서버를 추가하지 않아도 테스트 환경을 구성할 수 있다.
정확하고 안전한 서버 라이징
필요한 자원만큼만 가상머신을 할당할 수 있으며, 사이징 예측이 불확실한 서버를 구성할 때에도 일단 확보된 리소스를 이용하여 할당한 후 쉽게 추가로 할당할 수 있다.
시스템 관리
마이그레이션 기능을 이용할 경우 운영 중인 가상머신의 중지 없이 가상머신을 다른 물리적인 서버로 이동시킬 수 있다.
- 하드웨어 장애
장애가 발생한 장비에 운영되던 가상머신을 다른 장빌 이동한 후 장애가 발생한 장비의 디스크 교체 후 다시 서비스로 투입 - 로드 벨런싱
특정 가상 서버나 가상 서버가 수행중인 물리적인 서버에 부하가 집중되는 경우, 여유있는 서버로 가상머신을 이동시킨다. - 업그레이드
장비의 CPU 추가나 메모리 추가, 디스크 증설 등과 같은 작업이 필요한 경우 다른 장비로 가상머신을 이동 시킨 후 업그레이드 작업을 수행한다.
이번에는 장치별로 어떻게 가상화를 하는 지 알아보도록 하자. 크게 CPU, 메모리, 입출력(I/O) 장치 에 대한 가상화를 살펴볼 것이다.
1.3.1 CPU 가상화
하이퍼바이져는 물리적 서버위에 존재하는 가상화 레이어를 통해 운영체제가 수행하는데 필요한 하드웨어 환경을 가상으로 만들어 준다. 일반적으로 가상머신을 하이퍼바이저라고 부르며, 서버 가상화 기술의 핵심이라고 할 수 있다. 주로 x86 계열 서버 가상화에 사용하는 편이다.
CPU 가상화의 기능은 아래와 같이 총 4개 정도를 꼽을 수 있다.
[CPU 가상화의 기능]
1. 하드웨어 환경 에뮬레이션
2. 실행환경 격리
3. 시스템 자원 할당
4. 소프트웨어 스택 보존분류는 플랫폼에 따른 분류와 위치에 따른 분류가 있으며, 플랫폼에 따른 분류는 어떤 프로그램 계열을 사용하는 지에 따라 분류되며, 위치별 분류는 가상화가 이뤄지는 계층에 대한 위치를 의미한다.
플랫폼별
- x86 계열: VMware, MS virtual server, Xen
- 유닉스 계열: POWER Hypervisor
- 메인 프레임 계열: z/VM, PR/SM
위치 별
- 베어메탈 하이퍼바이저: 하드웨어와 호스트 운영체제 사이에 위치하며, 반가상화와 완전가상화로 분류
- 호스트 기반 하이퍼바이저: 호스트 운영체제와 게스트 운영체제 사이에 위치
플랫폼 별은 프로그램의 특징에 따른 분류이기 때문에, 이번 장에서는 위치별로 어떻게 다른지에 대해 구체적으로 살펴보자.
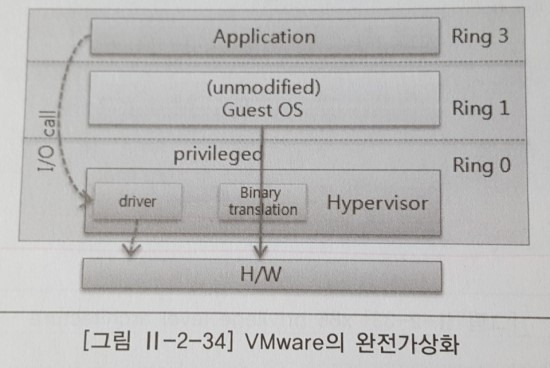
1.3.1.1 완전 가상화
CPU 뿐만 아니라 메모리, 네트워크 장치 등 모든 자원을 하이퍼바이저가 직접 제어 및 관리하기 때문에 어떤 운영체제라도 수정하지 않고 설치가 가능한 장점이 있다. 하이퍼바이저가 직접 제어하기 때문에 성능에 영향을 미치며, 자원들이 하이퍼바이저에 너무 밀접하게 연관돼있어 운영 중인 게스트 운영체제에 할당된 CPU나 메모리 등의 자원에 대한 동적변경 작업이 단일 서버 내에서는 어렵다. 자원 동적 변경은 솔루션의 도움을 받아야 하는 특징이 있으며, 장점으로는 하이퍼바이저상에서 변경되지 않은 상태로 실행될 수 있지만, Para Virtualization에 비해 속도가 느리다는 단점이 존재한다.
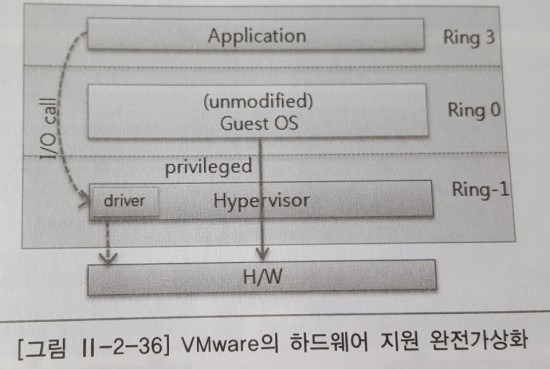
1.3.1.2 하드웨어 지원 완전 가상화
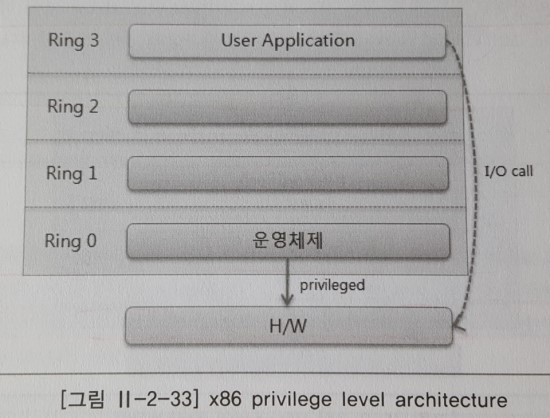
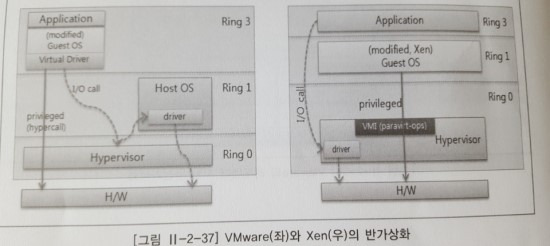
완전 가상화 방식 중 Intel VT-x, AMD-V CPU의 하드웨어에서 제공하는 가상화 기능을 이용한다. 가상머신의 운영체제는 Ring 0에서 수행되어 privileged 명령어에 대해 추가로 변환 과정이 필요없으며, 하이퍼바이저를 거쳐 바로 하드웨어로 명령이 전달돼 빠른 성능을 보장한다.
1.3.1.3 반가상화
previleged 명령어를 게스트 운영체제에서 hypercall로 하이퍼바이저에 전달하고 priviledge 레벨에 상관없이 하드웨어로 명령을 수행시킨다. (* Hypercall: 게스트 운영체제에서 요청을 하면 하이퍼바이저에서 바로 하드웨어 명령을 실행하는 call)
CPU와 메모리 자원의 동적 변경이 서비스의 중단 없이 이루어질 수 있으며 완전 가상화에 비해 성능이 뛰어나다.
- 반가상화의 경우 privileged 명령어를 직접 호출하므로 속도는 빠르나 커널을 변경해야 한다.
- 완전 가상화의 경우 모듈과 통신을 통해 처리하므로 속도는 느리나 커널 변경이 없다.
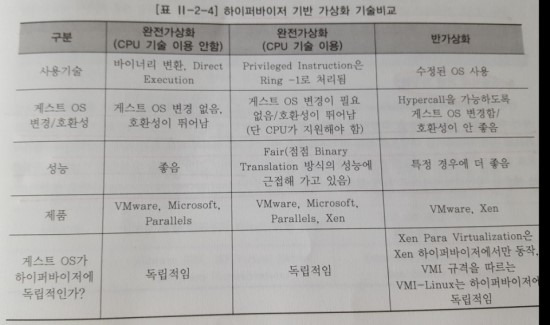
하이퍼바이저 기반의 가상화에 대해서 비교 및 정리해보자면, 아래의 표와 같다.
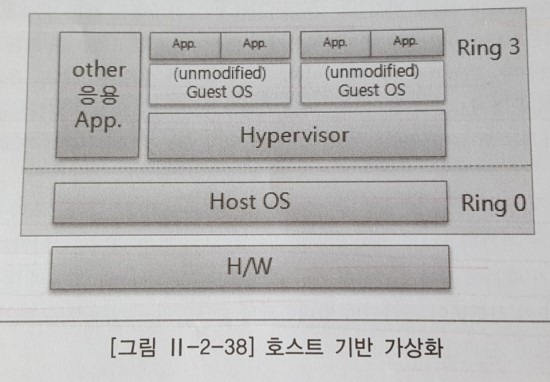
1.3.1.4 호스트 기반 가상화
완전한 운영체제가 설치되고 가상화를 담당하는 하이퍼바이저가 호스트 운영체제 위에 탑재되는 방식의 가상화이다. 다른 가상화 환경에 비해 성능은 물론 자원 관리 능력 측면에서도 제약 사항이 많은 편이며, 주로 테스트 환경에서 많이 사용되며 최근에는 사용하지 않는다. 아주 오래된 하드웨어와 그 하드웨어를 지원하는 특정 운영체제에서만 수행되어야 하는 애플리케이션을 가상화 기반에서 운영하는 경우에 사용할 수 있다.
1.3.1.5 컨테이너 기반 가상화
호스트 운영체제 위에 가상의 운영체제를 구성하기 위한 운영 환경 계층을 추가하여 운영체제만을 가상화한 방식이다. 특장으로는 전체 하드웨어를 대상으로 하는 하이퍼바이저 기반 가상화 방식에 비해 훨씬 적게 가상화 한다.
컨테이너 기반의 가상화는 가상화 수준이 낮기 때문에 다른 방식에 비해 빠른 성능을 보여주지만 자원간 격리 수준이 낮아 하나의 가상 운영체제에서 실행되는 애플리케이션의 자원 사용에 따라 다른 가상화 운영체제가 영향을 받는 단점이 있다. 또한 보안 취약성에 의해 모든 가상 운영체제에 문제가 발생할 수 있으며, 호스트 운영체제를 공유하기 Eians에 호스트 원영체제의 문제가 전체 가상 운영체제에도 영향을 미치게 된다. (* 가상운영환경: 컨테이너 기반 가상화 방식에서 가상화를 지원하는 계층)

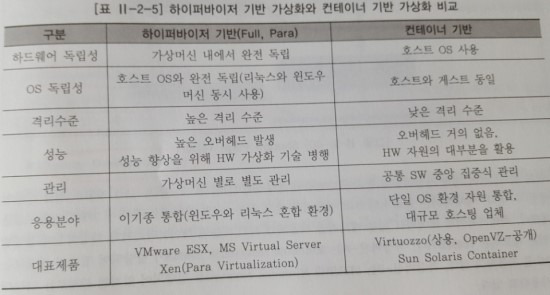
하이퍼바이저 기반의 가상화와 컨테이너 기반의 가상화에 대한 차이는 아래 표의 내용과 같다.
1.3.2 메모리 가상화
운영체제는 메모리를 관리하기 위해 물리주소와 가상주소를 사용하고 있다. 물리주소는 0 ~ 실제 물리적인 메모리 크기를 표현한 것이며, 가상 주소는 하나의 프로세스가 가리킬 수 있는 최대 크기를 표현한 것이다. 32비트 운영체제의 경우 4GB 까지 가능하다. 가상 주소 값의 위치(VPN,Virtual Page Number)와 물리적 주소 위치(MPN,Machine Page Number)를 매핑하는 과정이 필요하며 이 때 page table을 이용한다.
VMware의 하이퍼바이저의 경우 VMkernel 이 해당하는데, 서비스 콘솔, 디바이스 드라이버들의 메모리 영역을 제외한 나머지 전체 메모리 영역을 모두 관리하면서 가상머신에 메모리를 할당하게 되며, 하이퍼바이저 내에 Shadow Page Table을 두어 가상 메모리 주소와 물리 메모리 주소의 중간 변환 과정을 가로챈다.
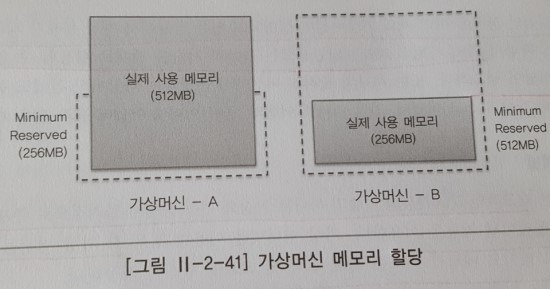
메모리 가상화 방법은 아래와 같이 3가지가 있다.
Memory Ballooning
예약된 메모리보다 더 많은 메모리를 사용하는 가상머신의 메모리 영역을 빈 값으로 강제로 채워 가상머신 운영체제가 자체적으로 swapping 하도록 한다.
Transparent Page Sharing
하나의 물리적인 머신에 여러 개의 가상 머신이 운영되는 경우 각 가상머신에 할당된 메모리 중 동일한 내용을 담고 있는 페이지는 물리적인 메모리 영역에 하나만 존재시키고, 모든 가상 머신이 공유하도록 한다.
Memory Overcommitment
2GB 메모리를 가진 물리적 장비에 512MB를 Minimum reserved를 가질 수 있는 가상 머신 5개를 수행할 수 있다.
1.3.3 I/O 가상화
하나의 물리적인 장비에 여러 개의 가상머신이 실행되고 있는 상황에서 가장 문제가 되는 것은 I/O에서의 병목현상이다. CPU 자원의 파티셔닝만으로는 가상화 기술을 제대로 활용할 수 없으며, I/O자원의 공유 및 파티셔닝이 필요하다. I/O 가상화와 관련된 기술로는 아래와 같다.
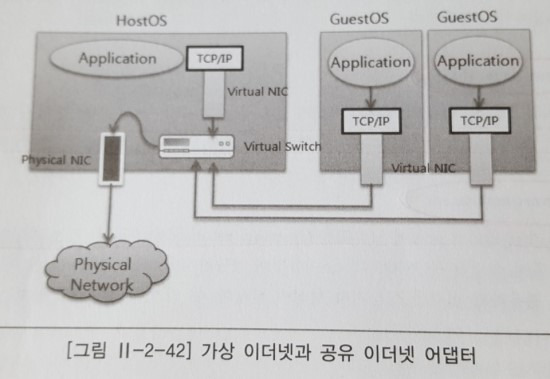
가상 인터넷
대표적인 I/O 가상화 기술로 물리적으로 존재하지 않는 자원을 만들어내는 에뮬레이션 기능을 이용한다. 각 가상 머신들 사이에 물리적인 네트워크 어댑터 없이도 메모리 버스를 통해 고속 및 고효율 통신이 가능하다. 가상 LAN 기술을 기반으로 네트워크 파티션도 가능하게 한다.
공유 어뎁터
여러 개의 가상머신이 물리적인 네트워크 카드를 공유할 수 있으며, 공유된 물리적 카드를 통해서 외부 네트워크와 통신이 가능하다. 하나의 자원을 이용하여 여러 가상머신이 공유하기 때문에 발생하는 병목현상은 피할 수 없다. 네트워크 어댑터 내에서 가상화를 지원하여 어댑터의 메모리 버퍼를 가상머신 별도 할당해 주어 하나의 물리적인 어댑터를 가상머신 하나에 할당하는 것과 동일한 효과를 낸다.
가상 디스크 어댑터
한 대의 서버가 여러 개의 가상머신을 구성할 경우 가장 문제가 되는 부분은 파이버 채널, 어댑터와 같은 I/O 어댑터 부족이다. 이에 대해 가상화된 환경에서 가상 디스크를 이용해 가상머신이 디스크 자원을 획득하는 방법에는2가지가 있다. 먼저, 내장 디스크의 경우 가상 I/O 레이어가 내장 디스크들을 소유하고 있고 이 내장 디스크들을 논리적 디스크 드라이브로 나눌 수 있다.
또 다른 하나는 외장 디스크의 경우인데, 먼저 가상 I/O 레이어가 파이버 채널 어댑터를 통해서 외장 디스크의 LUN(Logical Unit Number, 논리 단위 번호) 을 획득한다. 이 후 가상 I/O 레이어가 자원을 논리적 디스크 드라이브로 다시 나누지 않고 바로 각 가상머신에 가상 디스크 어댑터를 통해서 분배한다. (* LUN(Logical Unit Number, 논리 단위 번호))
여러 개의 하드 디스크에 중복된 데이터를 저장하는 기술인 RAID의 저장공간 번호를 의미한다. 즉, RAID를 구성하는 일부 혹은 전체공간을 의미한다.
'Certification > ADP&ADsP 🪪' 카테고리의 다른 글
| [ADP&ADsP] 5. 데이터 분석 기획 Ⅱ : 분석 마스터 플랜 (4) | 2024.10.20 |
|---|---|
| [ADP&ADsP] 4. 데이터 분석 기획 Ⅰ : 데이터 분석 기획의 이해 (5) | 2024.10.19 |
| [ADP/ADsP] 2. 데이터 처리 기술 Ⅰ : 데이터 처리 프로세스 (1) | 2024.10.16 |
| [ADP/ADsP] 1. 데이터 이해 (7) | 2024.10.16 |