[데이터 분석] 19. 차원 축소 (Dimensional Reduction) Ⅰ : PCA

1. 차원 축소란?
일반적으로 현실 세계의 문제는 가공되지 않은 데이터를 처리해야한다. 하지만, 대부분의 머신러닝 모델의 경우 고차원의 데이터를 입력으로 사용하면 학습속도가 느려지게 되고, "차원의 저주"라는 관측 단계 상 메모리 사용이 기하급수적으로 증가하는 현상이 나타난다. 뿐만 아니라, 과대적합의 위험성도 존재하여, 학습을 하는 전반적인 괒어에서 어려움을 겪을 수 있다. 위와 같은 이유로 데이터에서 불필요한 정보들을 제거해주기 위해서 수행하는 작업을 차원 축소 라고 부른다.
2. 차원 축소를 위한 접근법
차원 축소를 하는 방법에는 크게, 투영과 매니폴드 학습이라는 2가지 방법이 존재하며, 아래에서 각 과정의 특징과 방법을 자세히 살펴볼 예정이다.
2.1 투영
현실문제에서 학습 데이터 샘플은 모든 차원에 걸쳐 균일하게 퍼져있을 경우가 매우 드물다. 오히려 많은 특성이 변화가 없거나, 다른 특성들과 매우 깊이 연관되어있는 경우가 많다. 다시 말해, 모든 학습 데이터 샘플이 고차원 공간에 존재하지만, 실제로는 저차원의 부분 공간에 놓여있다고 할 수 있다. 예를 들어, 아래 그림과 같은 3차원에 데이터가 원 모양으로 분포한다고 가정해보자.

위의 그림에서, 모든 데이터 샘플은 거의 평면인 상태로 놓여져 있으며, 회색 사각형으로 표시한 부분이 고차원 공간 내 저차원 부분 공간이라고 가정해보자. 위의 부분 공간을 위에서 내려다보면 아래 그림과 같이 데이터가 분포할 것이다.

이렇게 원본 데이터는 특징이 3개가 존재하는 고차원 데이터였으나, 평면에 놓음으로써 특징이 2개인 부분 공간 상의 데이터로 변환해 데이터의 분포를 확인하기가 이전 대비 훨씬 수월해졌다. 하지만, 위의 방법이 항상 좋은 방법만은 아닌 이유가 있다. 예를 들어 아래 그림과 같이 스위스 롤 형태로 데이터가 3차원의 공간에 존재한다고 해보자.

위의 그림을 2차원의 평면에 투영시킨다면, 해당 공간을 가득 매울 수 있게되어 정확한 데이터 분포를 파악하기 어려울 수 있다. 만약 확인을 하고 싶다해도, 위의 그림과 같이 데이터 별로 색을 입히는 등 별도의 추가 작업이 진행되어야 확인이 가능할 것이다. 이처럼 데이터 셋의 공간이 뒤틀려있거나, 휘어있는 경우에는 투영을 하는 방법으로 확인하는 것을 어렵다. 이를 위해 고안된 방법이 아래에서 설명할 매니폴드 학습 방법이다.
2.2 매니폴드 학습
매니폴드(manifold) 라는 단어를 통해서 알 수 있듯이, 고차원 공간에서 휘어지거나 뒤틀린 저차원 부분 공간을 의미한다. 앞서 살펴 본 스위스롤 형태의 데이터도 매니폴드 데이터의 한 형태이다. 이를 일반화하게 되면, d 차원의 매니폴드 데이터는 d차원의 초평면에서 볼 수 있는 n 차원 공간의 일부이다. (이 때, d < n 이어야 한다.) 결과적으로 매니폴드 학습에 대해 한 줄로 표현해보자면 아래와 같이 말할 수 있다.
매니폴드 학습이란, 많은 차원 축소 알고리즘이 학습 데이터 샘플이 놓여있는 매니폴드를 모델링하는 식으로 동작한다.
물론 이에 대한 전제 조건으로 바로 처리할 작업이 저차원의 매니폴드 공간에 표현되면, 더 간단해질 수 있다. 앞서 본 스위스롤 형태의 데이터를 예시로 생각해보자. 해당 데이터를 2차원의 초평면에 펼치면 아래와 같은 그림으로 데이터를 표현할 수 있다.

위의 왼쪽 그림의 경우, 결정경계가 복잡해보이지만, 오른쪽 그림은 결정경계가 단순해서 직선으로 구분하기 쉽다. 하지만, 앞서 말한 가정이 항상 유효한 것은 아니므로 유의해야되는 부분이다. 정리해보자면, 모델을 학습시키기 전에 학습 데이터 세트의 차원을 감소시키면, 훈련 속도가 빨라지지만, 항상 더 낫거나 간단한 솔루션이 되는 것은 아니며, 데이터 셋에 매우 의존적이라는 단점이 존재함을 명확히 인지하자.
3. 주성분 분석(PCA)
차원축소 알고리즘들 중에서 가장 대표적인 알고리즘으로 데이터에 가장 가까운 초평면을 정의해, 데이터를 투영하는 방식으로 데이터의 차원을 축소하고, 주요 성분을 찾아내는 알고리즘이다.
3.1 분산 보존
저차원의 초평면에 학습 데이터를 투영하기 전, 투영하고자 하는 초평면이 올바른지를 먼저 확인해야한다. 예를 들어 데이터의 분포가 아래 그림과 같고, 분포에 따라 표시한 3가지 선에서 데이터를 투영한다고 가정할 때, 각각의 선에서의 데이터 분포를 표현한 것을 살펴보자.

위의 그림에서 보면, 데이터의 분포에 있어 3가지 선으로 차원을 축소하는 방향을 표현했는데, 이 중 실선으로 표시했을 때의 데이터가 가장 선 위에 고르게 분포하고 있고, 간격이 가장 짧은 점선으로의 차원 축소 시, 데이터의 분포가 가장 조밀하게 분포하는 것을 볼 수 있다.
PCA에서는 실선에서의 데이터 분포와 같이, 데이터의 분산을 최대화하는 방향을 정보의 손실을 최소화하는 방향으로 판단하며, 해당 방향으로 데이터의 차원을 축소하는 것이 합리적이라고 판단한다.
3.2 주성분
방금 전 언급했듯이, PCA 알고리즘은 학습 데이터의 분산이 최대가 되는 방향으로 데이터를 축소하기 때문에, 데이터의 분산이 최대인 축을 찾는 것이 목표라고도 할 수 있다. 앞서 본 데이터를 예시로 들자면, 실선으로 표현된 축이 첫 번째 축으로 선택되며, 이 후 다른 축을 찾을 때는 직전에 찾은 축에 수직이면서, 분산이 최대가 되는 축을 찾게 된다. 때문에, 위의 예시에서는 분산이 가장 작긴하나, 첫 번째 축과 수직을 이루는 간격이 가장 짧은 점선 방향을 두번째 축으로 선택하는 것이다.
이 때, i 번째 축을 정의하는 단위 벡터를 가리켜, i 번째 주성분이라고 표현하며 추출 단계는 다음과 같다.
① 데이터 표준화 및 전처리
② 공분산 행렬 구성
③ 공분산 행렬의 고유값과 고유벡터 계산
④ 고유값을 내림차순으로 정렬, 고유벡터 순위 계산
이렇듯, 고차원의 데이터인 경우에 데이터셋에 존재하는 차원 수 만큼 이전 축에 직교하는 주성분의 축을 찾게 된다. 이런 주성분은 특이값 분해(SVD, Single Value Decomposition)라는 표준행렬분해기술을 이용하며, 학습 데이터 행렬인 X를 3개 행렬의 점곱으로 분해한다. 파이썬에서는 numpy 라이브러리 내 svd() 함수를 사용해서 계산할 수 있으며, R에서도 svd() 함수를 사용해서 확인할 수 있다.
import numpy as np
import pandas as pd
from sklearn.decomposition import PCA
# 데이터 생성
## 가중치 및 편향 설정
np.random.seed(4)
m = 60
w1, w2 = 0.1, 0.3
noise = 0.1
## 원본데이터 생성
## - 3차원의 데이터를 생성
angles = np.random.rand(m) * 3 * np.pi / 2 - 0.5
X = np.empty((m, 3))
X[:, 0] = np.cos(angles) + np.sin(angles)/2 + noise * np.random.randn(m) / 2
X[:, 1] = np.sin(angles) * 0.7 + noise * np.random.randn(m) / 2
X[:, 2] = X[:, 0] * w1 + X[:, 1] * w2 + noise * np.random.randn(m)
## SVD 과정
## -주성분이 2개인 것으로 가정
X_centered = X - X.mean(axis=0)
U, s, Vt = np.linalg.svd(X_centered)
c1 = Vt.T[:, 0]
c2 = Vt.T[:, 1]
[실행결과]
[0.93636116 0.29854881 0.18465208]
[-0.34027485 0.90119108 0.2684542 ]# 필요한 라이브러리
library(stats)
# 데이터 생성
## 가중치 및 편향 설정
set.seed(4)
m <- 60
w1 <- 0.1
w2 <- 0.3
noise <- 0.1
## 원본 데이터 생성
## - 3차원의 데이터를 생성
angles <- runif(m, min = -0.5, max = 3 * pi / 2 - 0.5)
X <- matrix(NA, nrow = m, ncol = 3)
X[, 1] <- cos(angles) + sin(angles) / 2 + noise * rnorm(m) / 2
X[, 2] <- sin(angles) * 0.7 + noise * rnorm(m) / 2
X[, 3] <- X[, 1] * w1 + X[, 2] * w2 + noise * rnorm(m)
# SVD 과정
# - 주성분이 2개인 것으로 가정
X_centered <- scale(X, center = TRUE, scale = FALSE)
svd_result <- svd(X_centered)
c1 <- svd_result$v[, 1]
c2 <- svd_result$v[, 2]
# 결과 출력
print(c1)
print(c2)
[실행결과]
0.9148193 0.3431607 0.2129469
0.3954832 -0.8680437 -0.3001554위의 코드에서 X_centered에 대한 코드는 PCA에서 데이터셋의 평균을 0이라고 가정한다. 때문에 원점에 맞추기 위해서 X 대신 X_centered 값을 모델 생성과정에서 사용했다. 만약 위의 예시처럼 PCA를 직접 구현하거나, 다른 라이브러리를 사용하는 경우에는 데이터를 원점에 반드시 맞추고 구현해야한다. 다음으로 U, s, Vt 에 대한 내용을 살펴보자. 앞서 언급한 데로 SVD를 계산하는 식은 아래와 같다.
$ Cov = \frac {1} {n-1} X^T X $
$ = \frac {1} {n-1} (U \sum V^T)^T (U \sum V^T) $
$ = \frac {1} {n-1} (V \sum U^T)^T (V \sum U^T) $
$ = \frac {1} {n-1} ( (V \sum V^T)^T )^2 $
따라서 U, s, Vt 는 svd() 함수를 통해 얻은 결과이며, 이 때 svd() 로 변환되는 값 중에 V에 해당하는 값이 실제로는 위 식의 결과 중 $V^T$ 에 해당하는 부분이므로, 별도로 잔차를 구한 것이다. 그리고 이 중 첫번째, 두번째 열을 주성분으로 한다는 내용이 코드에서 각각 C1, C2에 할당된다는 내용이다.
3.3 투영하기
초평면은 분산을 가능한 최대로 보존하는 부분 공간이라고 설명했다. 또한 이 부분공간은 초기 d개의 주성분으로 정의했으며, 그렇기 때문에 원본의 차원을 d 차원으로 축소해야된다고도 언급했다. 투영을 하기 위한 수학적인 방법은 행렬 X와 첫 d 개의 주성분을 담은 행렬 $ W_d $ 를 점곱하면 된다.
$ {X}_{d-proj} = X \cdot {W}_{d} $
또한 위의 수식을 코드로 구현하자면, 아래와 같이 구현할 수 있다.
W2 = Vt.T[:, 2]
X2D = X_centered.dot(W2)
print(X2D)W2 <- svd_result$v[, 3]
X2D <- X_centered %*% W2
print(X2D)추가적으로 위의 결과와 함께 원천 데이터와도 비교해보자. 이 때 원천데이터는 X 가 아닌 X_centered 를 사용한다.
print(X_centered.shape) # (60, 3)
print(X_centered[:, 0])
print(X_centered[:, 1])
print(X_centered[:, 2])cat("Dimensions of X_centered: ", dim(X_centered), "\n")
cat("X_centered[, 1]: \n")
print(X_centered[, 1])
cat("X_centered[, 2]: \n")
print(X_centered[, 2])
cat("X_centered[, 3]: \n")
print(X_centered[, 3])지금까지의 내용을 PCA 관련 라이브러리들을 이용해서 간단하게 구현하자면 다음과 같이 할 수 있다.
pca = PCA(n_components=2) # 차원을 2차원으로 줄이는 모델
x2d = pca.fit_transform(X) # 모델 학습
print(pca.components_)library(stats)
pca_result <- prcomp(X, center = TRUE, scale. = FALSE, rank. = 2)
x2d <- pca_result$x
cat("PCA Components: \n")
print(pca_result$rotation[, 1:2]) # 첫 두 개의 주성분 출력학습이 완료되면 모델 내의 components_ (파이썬 기준) 변수를 통해 주성분을 확인해볼 수 있다. 이 때 주성분은 행 벡터 형식으로 저장되어 있으므로, 아래와 같이 전치를 시켜줘야 우리가 원하는 결과로 나오게 된다.
print(pca.components_.T)cat("Transposed PCA Components: \n")
print(t(pca_result$rotation[, 1:2]))추가적으로 주성분을 설명하는 분산에 대한 정보를 확인하고자 한다면, 파이썬 기준으로는 explained_variance_ratio_ 변수를, R의 경우에는 관련 변수가 없기에 아래 코드와 같이 추가적인 계산을 통해서 확인할 수 있다.
print(pca.explained_variance_ratio_)# 각 주성분의 설명된 분산 비율 계산
explained_variance_ratio <- pca_result$sdev^2 / sum(pca_result$sdev^2)
# 설명된 분산 비율 출력
cat("Explained Variance Ratio: \n")
print(explained_variance_ratio[1:2]) # 첫 두 개의 주성분의 분산 비율 출력3.4 적절한 차원 수
축소할 차원 수는 충분한 분산이 될 때까지 더 해야할 차원 수를 선택하는 것이 좋다. 또한 시각화까지 고려할 경우 차원을 2~3개로 줄이는 것이 일반적이다. 구체적인 과정은 다음과 같다.
먼저, 차원 축소 없이 PCA를 계산한 후, 훈련 데이터의 분산 중 95% 로 유지하는 데 필요한 최소한의 차원 수를 계산한다. 코드로는 다음과 같이 구현할 수 있다.
from sklearn.decomposition import PCA
...
pca = PCA()
pca.fit(X_train)
cumsum = np.cumsum(pca.explained_variance_ratio_)
d = np.argmax(cumsum >= 0.95)
print(d, cumsum[d])
[실행결과]
153 0.9504095236698549library(stats)
...
pca_result <- prcomp(X_train, center = TRUE, scale. = FALSE)
explained_variance_ratio <- pca_result$sdev^2 / sum(pca_result$sdev^2) # 설명된 분산 비율 계산
cumsum_variance <- cumsum(explained_variance_ratio) # 누적 설명된 분산 비율 계산
d <- which(cumsum_variance >= 0.95)[1] # 95% 이상을 설명하는 주성분의 개수 찾기
[실행결과]
153 0.9504095236698549
다음으로 PCA 모델의 매개변수 중 하나인 n_components 값을 앞서 구한 d 값으로 설정해서 PCA 모델을 다시 생성한다. 하지만 유지하려는 주성분의 수를 지정하기 보다는 보존하려는 분산의 비율을 n_components 값에 기입해주는 것이 좋으며, 값은 0.0 ~ 1.0 사이의 값으로 입력한다.
pca = PCA(n_components=0.95)
X_reduced = pca.fit_transform(X_train)
print(pca.n_components_)
np.sum(pca.explained_variance_ratio_)pca_result <- prcomp(X_train, center = TRUE, scale. = FALSE)
explained_variance_ratio <- pca_result$sdev^2 / sum(pca_result$sdev^2)
cumsum_variance <- cumsum(explained_variance_ratio)
n_components <- which(cumsum_variance >= 0.95)[1]
X_reduced <- pca_result$x[, 1:n_components]
cat("Number of components: ", n_components, "\n")
cat("Cumulative explained variance: ", sum(explained_variance_ratio[1:n_components]), "\n")3.5 압축을 위한 PCA
위의 과정을 통해서 알 수 있듯이, 차원을 축소하고난 후에는 학습 데이터 셋의 크기도 줄어든다. 실제로 위의 예시를 수행하기 전에는 784 개의 특성을 갖고 있었으나, 차원이 축소되면서 153개로 줄어들었다. 즉, 분산은 유지되지만, 데이터셋은 원본 크기의 약 20%가 된 것이다.
PCA 투영 변환을 반대로 적용하게되면, 차원을 되돌릴 수는 없지만 완벽하게 복원되기 어려우며, 원본 데이터와 재구성 데이터 간의 평균 제곱 거리 만큼의 오차가 존재하게 된다. 이를 가리켜, 재구성 오차(Reconstruction Error)라고 부른다. 아래 코드를 통해서 좀 더 살펴보도록 하자.
pca = PCA(n_components=154)
X_reduced = pca.fit_transform(X_train)
X_recovered = pca.inverse_transform(X_reduced)
# mnist 이미지 출력 함수 선언
def plot_digits(instances, images_per_row=5, **options):
size = 28
images_per_row = min(len(instances), images_per_row)
images = [instance.reshape(size,size) for instance in instances]
n_rows = (len(instances) - 1) // images_per_row + 1
row_images = []
n_empty = n_rows * images_per_row - len(instances)
images.append(np.zeros((size, size * n_empty)))
for row in range(n_rows):
rimages = images[row * images_per_row : (row + 1) * images_per_row]
row_images.append(np.concatenate(rimages, axis=1))
image = np.concatenate(row_images, axis=0)
plt.imshow(image, cmap = matplotlib.cm.binary, **options)
plt.axis("off")
# 한글출력
plt.rcParams['font.family'] = 'NanumBarunGothic'
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['axes.labelsize'] = 14
plt.rcParams['xtick.labelsize'] = 12
plt.rcParams['ytick.labelsize'] = 12
# 시각화
plt.figure(figsize=(7, 4))
plt.subplot(121)
plot_digits(X_train[::2100])
plt.title("원본", fontsize=16)
plt.subplot(122)
plot_digits(X_recovered[::2100])
plt.title("압축 후 복원", fontsize=16)
plt.savefig("images/dimension_reduction/mnist_compression_plot")# 필요한 라이브러리
library(ggplot2)
library(gridExtra)
library(grid)
# PCA 수행
pca_result <- prcomp(X_train, center = TRUE, scale. = FALSE)
# 주성분을 154개로 차원 축소
X_reduced <- pca_result$x[, 1:154]
# 복원된 데이터 (X_recovered)
X_recovered <- X_reduced %*% t(pca_result$rotation[, 1:154]) + matrix(colMeans(X_train), nrow = nrow(X_reduced), ncol = ncol(X_reduced), byrow = TRUE)
# MNIST 이미지 그리기 함수 정의
plot_digits <- function(instances, images_per_row = 5) {
size <- 28
n_instances <- nrow(instances)
images_per_row <- min(n_instances, images_per_row)
n_rows <- ceiling(n_instances / images_per_row)
par(mfrow = c(n_rows, images_per_row), mar = c(0.1, 0.1, 0.1, 0.1))
for (i in 1:n_instances) {
image_matrix <- matrix(instances[i, ], nrow = size, ncol = size, byrow = TRUE)
image(1:size, 1:size, t(image_matrix)[, ncol(image_matrix):1], col = gray.colors(256), axes = FALSE)
}
}
# 원본 이미지와 복원된 이미지 비교 시각화
par(mfrow = c(1, 2)) # 1x2 배열로 출력
plot_digits(X_train[seq(1, nrow(X_train), by = 2100), ]) # 원본 이미지 출력
title("원본", line = -2, cex.main = 1.5)
plot_digits(X_recovered[seq(1, nrow(X_recovered), by = 2100), ]) # 압축 후 복원 이미지 출력
title("압축 후 복원", line = -2, cex.main = 1.5)
4. 실습: Wine 데이터셋의 주성분 추출하기
앞서 이론적으로 살펴본 내용을 확인해보기 위해 Wine 데이터 셋을 다운 받아 와인 클래스를 구별하는 데 필요한 주성분에는 어떤 것들이 있는 지 확인해보도록 하자. 위의 목표를 위해 이번 실습에서는 크게 아래 4단계로 주성분 추출을 진행할 예정이다.
① 데이터를 표준화, 전처리한다.
② 공분산 행렬을 계산한다.
③ 공분산 행렬의 고유값과 고유벡터를 구한다.
④ 고유값을 내림차순으로 정렬해 고유벡터의 순위를 계산한다.
먼저, 데이터에 대한 전처리를 진행해보자. 전처리 과정에서는 표준화 및 공분산을 계산해준다. 구체적인 코드는 아래와 같다.
import numpy as np
import pandas as pd
import matplotlib
from matplotlib import pyplot as plt
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from ucimlrepo import fetch_ucirepo
matplotlib.use("MacOSX")
# 데이터 로드
wine = fetch_ucirepo(id=109)
x, y = wine.data.features, wine.data.targets
# 매타데이터 및 변수 정보 확인
print(wine.metadata)
print(wine.variables)
# 1. 데이터 전처리
# 1.1 7:3 으로 데이터 split
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3, stratify=y, random_state=0)
# 1.2 표준화 처리
sc = StandardScaler()
x_train_std = sc.fit_transform(x_train)
x_test_std = sc.fit_transform(x_test)
# 2. 공분산 계산
cov = np.cov(x_train_std.T) # 공분산 행렬 계산
eigen_vals, eigen_vector = np.linalg.eig(cov) # 고유값 분해 -> 고유 벡터, 고유값
print('고유값 \n%s' % eigen_vals)
total = sum(eigen_vals)
exp_val = [(i / total) for i in sorted(eigen_vals, reverse=True)]
cum_var_exp = np.cumsum(exp_val)
plt.bar(range(1, 14), exp_val, alpha=0.5, align='center', label='Individual Explained Varience')
plt.step(range(1, 14), cum_var_exp, where='mid', label='Cumulative Explained Varience')
plt.ylabel('Explained Varience Ratio')
plt.xlabel('Principal Component Index')
plt.legend(loc='best')
plt.tight_layout()
plt.savefig('/Users/kilhyunkim/Pictures/Variance Sum to Component Index.png')
plt.show()library(ggplot2)
library(caret)
library(scales)
# 1. 데이터 로드 및 전처리
# wine 데이터셋 로드
wine <- read.csv("https://archive.ics.uci.edu/ml/machine-learning-databases/wine/wine.data", header = FALSE)
# 컬럼 이름 지정
colnames(wine) <- c("Class", "Alcohol", "Malic_acid", "Ash", "Alcalinity_of_ash",
"Magnesium", "Total_phenols", "Flavanoids", "Nonflavanoid_phenols",
"Proanthocyanins", "Color_intensity", "Hue", "OD280_OD315", "Proline")
# x와 y로 분리
x <- wine[, -1]
y <- wine$Class
# 1.1 데이터 분리 (7:3 비율)
set.seed(0)
trainIndex <- createDataPartition(y, p = 0.7, list = FALSE)
x_train <- x[trainIndex, ]
x_test <- x[-trainIndex, ]
y_train <- y[trainIndex]
y_test <- y[-trainIndex]
# 1.2 표준화 처리
scaler <- preProcess(x_train, method = c("center", "scale"))
x_train_std <- predict(scaler, x_train)
x_test_std <- predict(scaler, x_test)
# 2. 공분산 계산
cov_matrix <- cov(x_train_std)
eigen_decomp <- eigen(cov_matrix)
eigen_vals <- eigen_decomp$values
eigen_vectors <- eigen_decomp$vectors
cat('고유값: \n', eigen_vals, '\n')
total_variance <- sum(eigen_vals)
explained_variance <- (eigen_vals / total_variance)
cumulative_variance <- cumsum(explained_variance)
# 막대 그래프와 누적 설명 분산 비율 시각화
df <- data.frame(
Principal_Component = 1:length(eigen_vals),
Explained_Variance = explained_variance,
Cumulative_Variance = cumulative_variance
)
ggplot(df, aes(x = Principal_Component)) +
geom_bar(aes(y = Explained_Variance), stat = "identity", fill = "steelblue", alpha = 0.7) +
geom_step(aes(y = Cumulative_Variance), color = "red", direction = "mid") +
scale_y_continuous(labels = percent_format()) +
labs(x = "Principal Component Index",
y = "Explained Variance Ratio",
title = "Variance Explained by Principal Components") +
theme_minimal()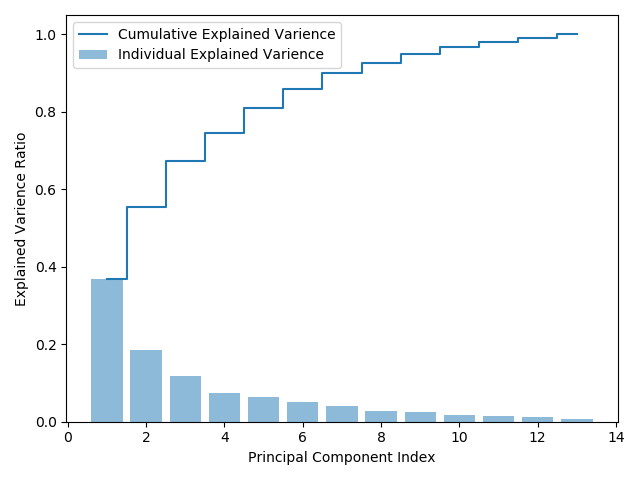
위의 공분산행렬계산 결과그래프를 살펴보면, 첫 번째 주성분은 전체 데이터의 분산에 대해 약 40%를 차지하고 있으며, 첫 2개 주성분으로는 전체 분산의 약 60% 이상을 설명할 수 있다. 다음으로 고유벡터를 생성하고, 투영해서 새로운 특성 부분 공간을 생성해보자. 코드는 다음과 같다.
# 3. 고유 벡터 생성 및 투영
# 3.1 고유 벡터 - 고유값 쌍(튜플형식)으로 구성 후, 내림차순으로 정렬
eigen_pairs = [(np.abs(eigen_vals[i]), eigen_vector[:, i]) for i in range(len(eigen_vals))]
eigen_pairs.sort(key=lambda k: k[0], reverse=True)
print(eigen_pairs)
# 3.2 투영 행렬 W 생성
# 정렬된 것 중에서 가장 큰 고유값 2개와 쌍을 이루는 고유 벡터들을 선택한다. (전체 분산의 약 60% 정도를 사용할 것으로 예상됨)
# 투영 행렬은 13 x 2 형식의 리스트로 저장함
w = np.hstack((eigen_pairs[0][1][:, np.newaxis],
eigen_pairs[1][1][:, np.newaxis]))
print(w)
# 4. PCA 부분공간 산출하기
# X' = XW ( 부분공간 : X' / X : 원본 , W : 투영행렬 )
x_train_pca = x_train_std.dot(w)
print(x_train_pca)
# 변환된 훈련데이터의 시각화
colors = ['r', 'g', 'b']
markers = ['s', 'x', 'o']
y_train_classes = y_train["class"].values
for label, color, marker in zip(np.unique(y_train_classes), colors, markers):
plt.scatter(x_train_pca[y_train_classes==label, 0],
x_train_pca[y_train_classes==label, 1],
c=color, label=label, marker=marker)
plt.xlabel('PC 1')
plt.ylabel('PC 2')
plt.legend(loc='lower left')
plt.tight_layout()
plt.savefig('images/dimension_reduction/wine_dim_reduction_result.png')
plt.show()# 필요한 라이브러리
library(ggplot2)
# 3. 고유 벡터 생성 및 투영
# 3.1 고유 벡터 - 고유값 쌍(리스트 형식)으로 구성 후, 내림차순으로 정렬
eigen_pairs <- lapply(1:length(eigen_vals), function(i) list(abs(eigen_vals[i]), eigen_vectors[, i]))
eigen_pairs <- eigen_pairs[order(sapply(eigen_pairs, function(x) x[[1]]), decreasing = TRUE)]
# 3.2 투영 행렬 W 생성
# 정렬된 것 중에서 가장 큰 고유값 2개와 쌍을 이루는 고유 벡터들을 선택한다.
w <- cbind(eigen_pairs[[1]][[2]], eigen_pairs[[2]][[2]])
print(w)
# 4. PCA 부분공간 산출하기
# X' = XW ( 부분공간 : X' / X : 원본 , W : 투영행렬 )
x_train_pca <- as.matrix(x_train_std) %*% w
print(x_train_pca)
# 5. 변환된 훈련 데이터의 시각화
# y_train 데이터가 벡터로 존재한다고 가정 (벡터로 변환 필요 시 as.vector 사용)
y_train_classes <- as.vector(y_train)
# 색상과 마커 설정
colors <- c('red', 'green', 'blue')
markers <- c(16, 17, 18)
# 데이터 프레임 생성 (시각화를 위해)
pca_data <- data.frame(PC1 = x_train_pca[, 1], PC2 = x_train_pca[, 2], Class = as.factor(y_train_classes))
# 시각화
ggplot(pca_data, aes(x = PC1, y = PC2, color = Class, shape = Class)) +
geom_point(size = 3) +
scale_color_manual(values = colors) +
scale_shape_manual(values = markers) +
labs(x = 'PC 1', y = 'PC 2', title = 'PCA of Wine Dataset') +
theme_minimal() +
theme(legend.position = "lower left")
위의 그래프 상으로 확인해보면, 데이터가 y축에 비해 x축을 따라 더 넓게 분포하는 것을 확인할 수 있다. 주성분은 고유값의 크기 순으로 정렬했기 때문에, 첫 번째 주성분의 분산이 가장 크다는 것도 확인할 수 있다.